背景
好像在今年四月份的时候,pmcaff 社区开放注册,在官网上线后的一两个月里,我们“优秀答主”群里几乎都在反馈,社区的质量下滑严重,主要表现在:问题重复、无人回答、精选文章陈旧、使用 BUG、产品学徒的作业出现在“待回答”里面等等。下滑的原因一部分是开放注册平均了社区用户质量,一部分问题来自产品运营的重心转移;于是在很长一段时间里,我很少上线,零散写了几篇文章。今天如果我是 pmcaff 的产品经理,我会通过以下几个点来做产品迭代。
存在的问题
pmcaff 社区是一个以交流为中心,以产品、UI、交互为目标,汇聚一类或多类从业者和爱好者的社区。交流其实是信息传递,pmcaff 的信息传递有两大模式:发文、提问。我今天要和大家一起分享的是提问这一块,根据反馈和自身体验,提问这块的问题非常大:
- 没有限制,没有门槛,造就了没有质量。
- 没有回报,没有收获,造就了没人回答。
- 没有算法,没有排序,造就了没有聚合分发。
- 没有标签,没有归类,造就了没有精准推荐。
- …
迭代的方法
针对上面的问题,我细化成两个大模块:第一:门槛;第二:算法。
做产品一定要系统和框架,没有框架和大局,产品骨架就不明确,功能就会遗漏,涉及到流程的可能就会死循环。系统的看待提问,可以归纳为两个重要的角色,提问者和回答者(我们把旁观者也当作回答者,只不过他的回答操作永远没有按下 Enter 键)。
提问者
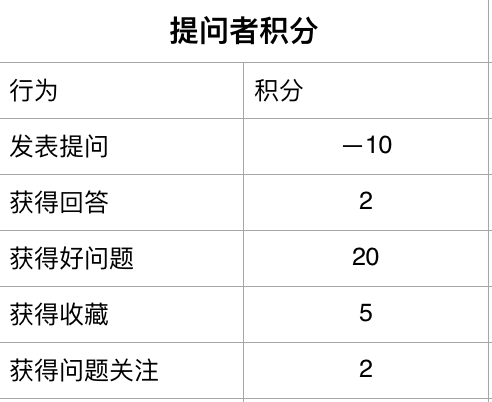
对于提问者,最直接的办法就是提高提问门槛,以下是我做得一个表,行为和积分权重可以根据运营后的数据再优化,“+”代表获得,“—”代表扣除
回答者
贡献回答是无私的,为了保证每个问题被尊重,每个答案有价值,那就必须告诉用户,不是所有人都适合对这类问题发表答案或者不是所有人都可以随便发表答案,诸如“卧槽”、“666,这个问题问得好”、“泻药,balabala”、“Nice 兄dei”的没有任何价值的回答,就扼杀在门槛

在一个以UGC为产物的的社区,提高一群贡献内容的用户发表内容的门槛,可能是个败招,但做为一个产品经理社区,在中国仍然属于一个小众社区,做细做精,保证质量再扩增数量可能更容易获得亲莱和驻扎,因为很多的“产品经理”在大多数公司都是个职位而已。
算法逻辑
算法逻辑我思考了很久,在现有的产品层单纯做算法没有意义,也比较棘手,我个人的看法是,提问者提出的问题肯定源自对产品的思考,那么问题就可以归类,我的想法分以下几点:
提问时必须选择问题属性,站在整个社区的角度看,所有的问题都有个总的归属关系,这个功能的展现形式不做限制:标签、主题等等都行
每个属性下的问题应该具有聚合一类用户的能力,比喻推荐,分发;为了能获取最新最热的内容,属性下的问题应该有个科学的排序算法
Pmcaff 的答案的排序现在做的超级烂,按时间和按认可数都不是一个最好的筛选项,而且对于排序在主动获取而不是被动检索的场景下,规则应该有算法来决定而不是手工筛选,下面这个回答仍然是第一位。

无论出于什么,一些普遍认为“水”的答案,在爆光上应该往后站站,这关乎社区的印象和用户体验。
具体实现
接下来就是具体实现这两块了,积分有积分规则,算法有算法规则
积分

积分只是一个方式,目的是提高社区创造内容的成本,因为在目前阶段能限制质量的也只有门槛了。
积分的数额设定依据人民币面额值:1,2,5,10…100,在我设计这个功能之初,积分和人民币一样,需要“赚取”和“花费”,所以在数值设定我就偷了个懒。提问之后在赚回“积分”的道路上并不坎坷,因为标记为好问题之后,剩下的时间都是获得积分。奖励积分遵循一个原则:为社区带来新用户的行为就大大奖励、活跃者多奖励。每天登录的奖励可以自行设置,是动态随机还是递增的,你来定。
排序
关于属性、标签以及推荐和分发是一个庞大的体系内容,今天不做展开,我今天主要分享关于答案的排序如何通过算法实现。在介绍之前,先削除大家的的一个心理障碍,“算法”其实没有那么高达上,就是实现一个功能的数学逻辑,要么是一个公式,要么是几个公式,要么是一个规则文档。
要做答案的排名,我们先整理出影响这个答案排名的一些指标:
从上面这张图可以得到和答案息息相关的以下几个信息:
- 发表时间
- 认可数量
- 水数量
- 分享数
- 评论数
那么算法就围绕这几个指标展开,这里切忌将一些“私有”属性列入到算法里面,如:答者的粉丝数、回答数、认可数等等。因为算法的意义就是让大家在同一个起跑线上,排名只由答案的自身属性决定。
我们先理一下常规的思路:第一:发表越早(越陈旧)的答案应该稍微靠后,因为理论上应该让新的评论给更多浏览者看到。第二:赞成和水之间应该有权衡关系,有一个衡量的指标来告诉算法当前的答案是属于认可还是不认可(水)。第三:评论和分享和总得浏览人数有关,不是评论越多答案越好,也不是分享越多答案越好。基于这些分析,我先给出算法公式

上面的公式以运算符号为间隔分成以下四个部分
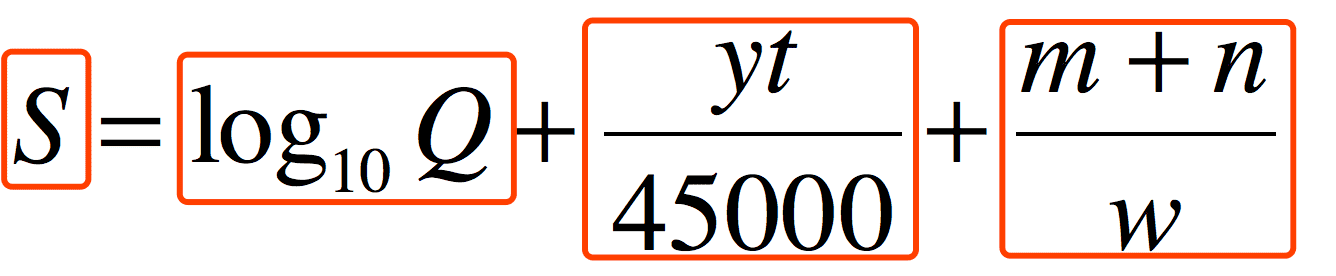
我们一个一个来看
字母S
S:每个答案最后的得分,程序就是根据这个值来把分值高的答案排在上面
右边第一部分

以10为底的对数,这里说一下,以10为底的对数和以 e 为底的对数,在很多算法中都会利用,爱数学函数的朋友可以多回顾下高中函数知识,在这里表示:当出现大家都认可这个答案现象之后,越到后面投认可票,对得分越不受影响。看看 Q 代表什么意思

上面公式中,x = 认可数量-水数量,表示这个答案在大家心中的认可程度。
当:认可数量 = 水数量,Q = 1
当:认可数量 != 水数量,Q = |x|,当差值不等于零,其实隐含告诉你一个信息,这个答案已经在“一边倒”了。
右边第二部分
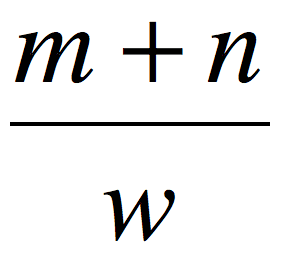
t = 答案发表时间 - 问题发表时间,t 可以直观看出这个答案够不够“新鲜”(离当前时间越近)。
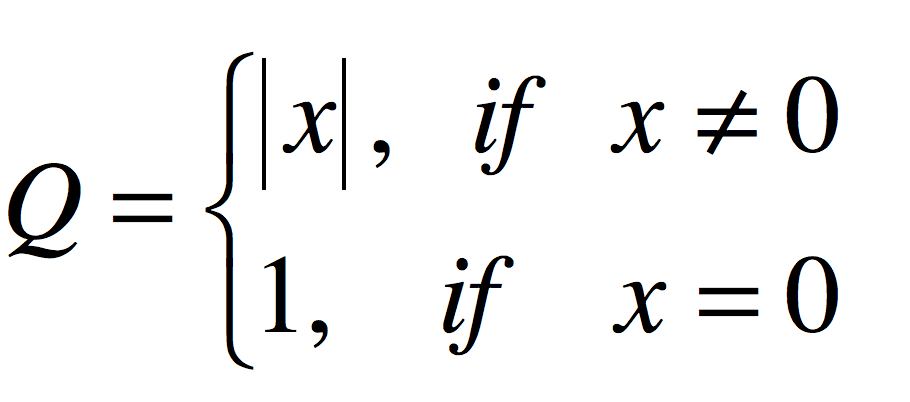
公式中 y 是个变量,当普遍认可这个答案的时候,y = 1;当普遍觉得这个答案很水的时候,y = -1;当两方观点不分伯仲,y = 0,右边第二部分值为0,也就是说,在争议非常大的时候,答案的排名已经和时间参数 t 没有关系了。
45000秒是个常数,等于12个半小时。从这个公式可以看出 t 是个固定的常数,越“新鲜”的答案会得到更高的分。
右边第三部分
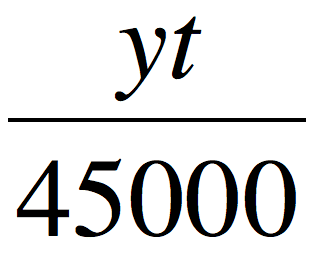
m:评论数。这里算人头(独立IP),1个人评论10条,m = 1。
n:答案分享数。
w:阅读数。
可以看出,如果浏览人数非常多,但和文章的交互(评论、转发、点赞、收藏等)非常少时,这部分值越趋近于0;可以有效筛掉一些标题党,让真正有价值的内容尽快赶上来。
再回头重新看一下公式
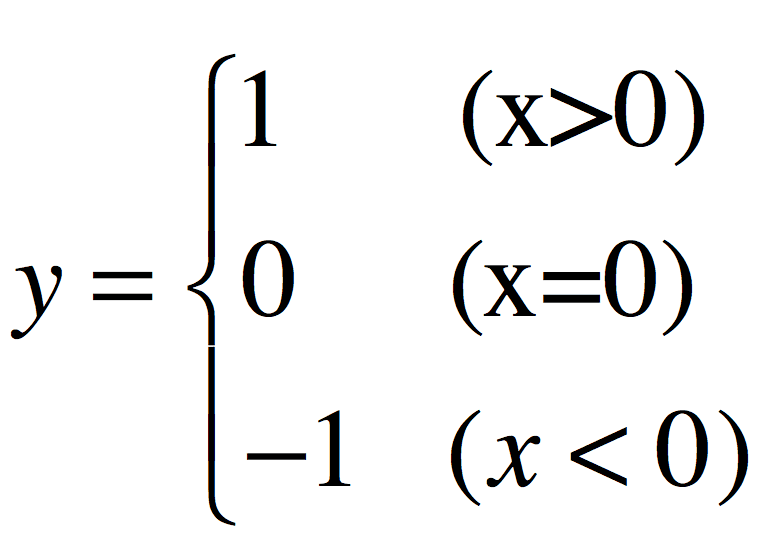
平时如果有研究的朋友应该已经发现了,这个算法就是根据大名鼎鼎的 Reddit 社区帖子排名算法修改的,我结合我要做的产品,将算法做了修改,在没有数据见证的情况下,好与坏我没办法给出答案。真正上线之后还是需要数据反馈,再次对算法“调教调教”。
最后
积分体系的产品,我相信任何一个规则,只要这个用户正常,最后的结果都是用户积分越来越多,大家可以考虑下到达一定的积分后,如何使用积分?关于后面这个算法从数学角度分析,还是有很多问题,有了答案的排序算法,那么问题该以什么样的算法呈现出来是个最关键的步骤,大家可以自行思考,后面更新的文章会给出答案。
