上篇文章分享了“余弦相似度”的理解和实例应用,今天和大家一起分享下热度算法。
21世纪注定是一个信息大爆炸的时代,我们不再担心获取信息的渠道有限,信息量狭窄等问题,互联网将世界各个地方的人、事、物巧妙的链接起来,相互交互,共同渗透……
那么在任何一个硬件设备上展示最有价值的内容,自然成了每个平台都需要思考的问题,所以排序问题就悠然而生,今天要分享的就是解决一些信息排序问题需要用到的“热度算法”。
本文结构如下
- 基本原理
- 实例分享
- 总结
热度算法的基本原理
任何一个算法都存在一个巧妙的思维转换,为了便于理解,这里我们形象的举一个例子。假设现在有一杯100摄氏度的水,我们将这杯水放在室内的桌子上,很快这杯水的温度会下降到和室温保持一致,那么能得到这样一个公式:
最后的温度T=初始温度T0-随时间衰减的温度Tt
那么我们现在假设存在一篇文章,这篇文章最后呈现在用户面前时候有一个衡量它新鲜度的值,那么我们就可以根据这个值来把成千上万的文章有序的排列下来,让那些新鲜度高的文章展示在前面,优先让用户看到,我们形象的把这个值称为文章当前的热度。那么一起看看下面的实例吧!!!
实例
我们以一个新闻报道为例来解释这个算法的逻辑。既然这个值是我们人为给添加的(没有哪篇文章真正存在热度),那么为了公平起见,我们把新闻类的报道分类,每一类都给一个初始的值(保证那些非常非常冷门的文章报道不至于在起跑线上就输了),好了,我们大致把报道类的文章分成:科技、金融、体育三个类别。那么最后的值P=P0-Pt。(Pt,随时间衰减的值)
初始值都一样吗
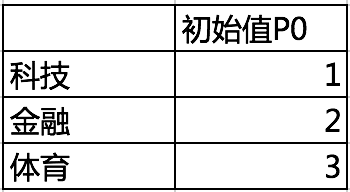
初始值P0
我们先抛开“这样设定的依据是什么?“的疑问,在很多时候,规定一项制度或规章,是解释不清的,比喻“为什么过往行人一定要靠右走?靠左走行不行?”
根据不同的产品,这个初始值可以调整,比喻某个体育报道的 App 他可以将体育的初始值调高一点,或者某个产品的用户数据体现出,金融类文章的点击率和收藏量很高,那么针对这些用户这类文章的初始值也可以微调高于其他类。
如上表,我们例子中的三类文章的初始值:
科技:P0=1
金融:P0=2
体育:P0=3
热度的衰减随时间的变化其衰减梯度是一样的吗
我们假设时间为24小时,由牛顿冷却定律,我们知道,任何一个向外散播热度的过程满足一个数学公式,下面是来自维基百科的“牛顿冷却定律:
一个较周围热的物体温度为T,忽略表面积以及外部介质性质和温度的变化.它的冷却速率(dT/dt)与该物体的温度与周围环境的温度C的差(T-C)成正比.
即dT/dt=-k(T-C).其中,t为时间,k为一个常数.
计算方法是: 对dT/dt=-k(T-C)进行积分,得 ln(T-C)=-kt+B (B为积分常数) (T-C)=e^(-kt+B) 公式1 设t=0,也就是物体的初温,上述公式1变成 (T0-C)=e^B 然后代入公式1得 T=C+(T0-C)e^-kt 算出B与k,代入t的值,就可以算出某个时间物体的温度.
科学的解释总是符合一点,balabala 一大堆,最后还是不知道说的啥。。。我们简化上面的内容,直接上公式
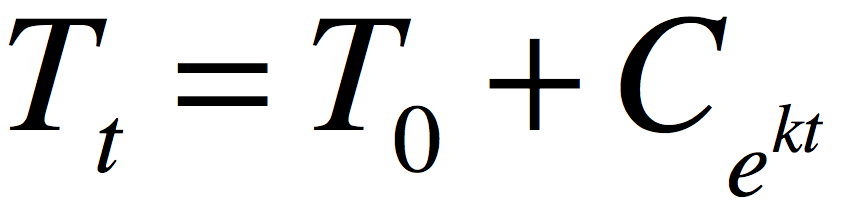
很明显,热度的衰减不是线性变化的,那么我们的文章冷却就可以参考这个定律(文章不可能说过十小时就掉10分,其变化也不是线性的)那么类似的,我们可以得到一个公式:
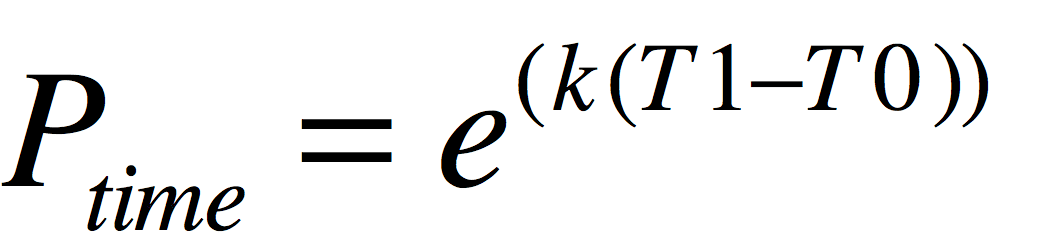
热度衰减公式
(有兴趣的可以去推导这个公式,为了不制造麻烦,现在你只需要记住这个公式就行,其中T0是发布文章时间,T1是当前时间,e=2.7182818284…)
最后的公式
经过上面的分析,最后公式就演变成:
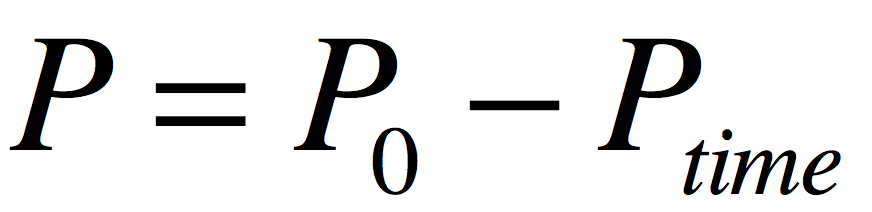
分值计算公式
这样一来,就可以根据初始值、衰减值,最后算出当前值,然后给文章排序。这里我们不做数学公式演示,有兴趣的可以自己制造数据尝试为100篇文章排一下序。
总结
热度算法应用中,我们首先明确我们的思路,以一个分值来衡量某篇文章的新鲜度和热门程度,然后以这个分值作为排序的标准。最后解决一些影响分值变化的因子最终得出具体的计算公式。
大家可以先思考下面几个问题,下篇文章将给出解答。
- 依据上面的公式,最后的分值 P 是不是会变成负数?比喻 08 年北京的奥运会的某篇报道……
- 很多 App 上的文章都有转发、收藏、点赞等功能,那么有这些因素存在后,算法该怎么“调教”?
如果你是一枚 PM 正在了解产品中相关的算法,我们可以一起交流学习,只会画原型、跟进项目、排期迭代这些技能似乎会被行业淘汰,机器学习、人工智能、搜索引擎、推荐算法等等热词如今已和产品经理四个字紧紧的凝固在一起了,这个系列文章会不断更新,我们一起加油,一起升值。
