有上篇和上上篇的基础,我们就可以针对性的对一个产品搭建出一个个性化推荐模型,在这个模型中,我们需要解决两个问题:
- 第一推荐什么。
- 第二哪些内容应该优先推荐。
上两篇文章很好的给出了具体的算法参考,大家可以回顾。
在进入这篇文章的正题之前,我们先一起解决上篇文章遗留的问题:
1.依据上面的公式,最后的分值 P 是不是会变成负数?比喻 08 年北京的奥运会的某篇报道……
2.很多 App 上的文章都有转发、收藏、点赞等功能,那么有这些因素存在后,算法该怎么调整?
先来解决第一个问题,我们看一下上篇文章中我们最后的公式为:
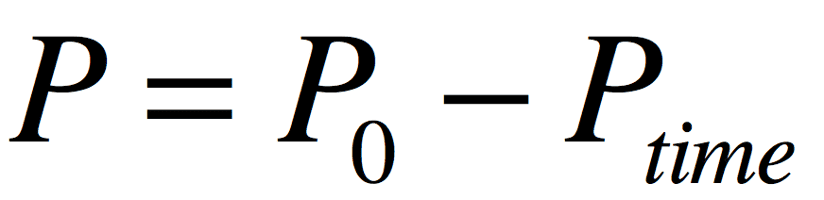
那么为了避免出现负数(其实负数并不影响算法的执行,只是在某些环境下,为了数据美观,我们尽量避免负数出现)这个问题很好调整,我们只需要将上面的公式做下微调
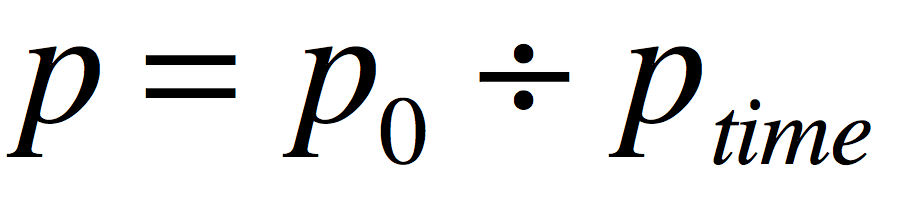
经过微调之后,热度值无限接近于零,这也符合实际,时间过去的越久,一篇文章的热度就越低。
我们知道任何一篇报道或文章都存在用户交互行为,像评论、收藏、点赞、转发等等行为是影响热度的重要指标,这个时候我们引入一个新的因子:用户行为分;我们用
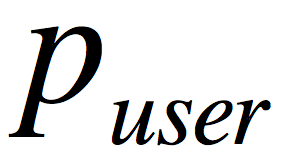
表示,
那么我的公式最后就调整为:
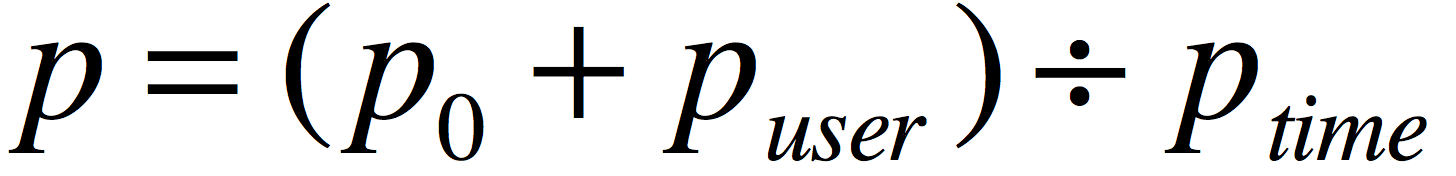
在算法执行初期,根据运营的数据和经验,合理制定用户行为分,例如:
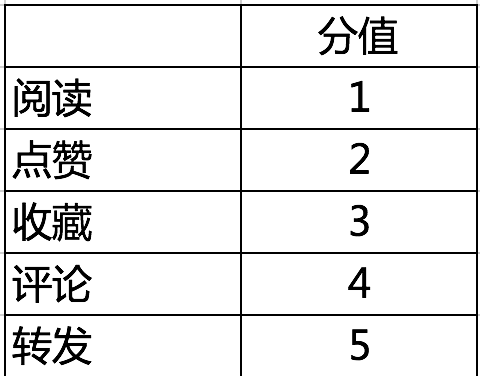
不同的产品这些分值可以调整,在算法实施过程中尽量保证各个影响因子能够调整配置。
好了,上面的问题解决了。看似很简单,做起来是很复杂的……
当你和我一样,顺着这个思路,一步一步将这些算法上线之后,并获得一定的数据反馈和领导的认可,恭喜你,你的内容产品已经顺利度过早期阶段,拥有几万或者十几万的日活。每当这个时候,你会发现由于这些内容在你所制定的算法驱动下呈现给用户,会出现以下几个问题:
1.内容太过集中
2.个性化和长尾化的内容都被埋没
抱着解决这两个问题的目的,是时候上个性化推荐了。个性化推荐一般有两种解决方案,基于内容的个性化推荐;基于用户的个性化推荐。这两种解决方案,用通俗的话解释:喜欢A的用户在某种程度上也喜欢和A相似的B;喜欢A的用户1和喜欢A的用户2,在某种程度上有一定的相似性,那么尽量把用户2喜欢的某个物品(或文章)B推荐给用户1。
这两种解决方案,市场上都有典型的代表产品,基于用户的协同过滤对用户的规模要求相当高,所以今天的文章内容我们就以基于内容的个性化推荐为例展开。
我们先来看看几个名词“特征向量、分词、关键词”,任何两篇文章或者两本书或者两个歌单,我们都可以用“特征向量”来标识目标的属性,文章、书籍、歌单是所有标签(关键词)的合集,那么标签越类似两个目标内容越相似。获得关键词的第一步是要讲目标进行拆分,为了简捷,我们以两篇文章为例:
1.分词
分词前面有提到过,分词有两个词库,正常词库和停用词库。正常词库类似一个规则,将目标文章按规则来分词;停用词库是去掉目标文章中没用的词,比喻:“了、吗、的、地”和“the、are、that”等之类的,因为这些词对分析没有任何作用,在分词前先剔除。
网络每天都在更新,正常词库和停用词库需要不断的更新,如果某篇文章中出现“疯狂打call”“尬聊”“扎心了,老铁”等词之后,机器算法是识别不了的。所以词库需要不断的更新,这些网上有很多,各种各样可供参考。
2.关键词
关键词是决定一篇文章的特征向量指标,有没有可能两篇文章的关键词重合的90%,但是讲的却是两件事呢?答案是肯定的。看个例子:
文章1:“支付宝和往年一样又开始集福分钱了”主要讲述支付宝的集福活动,“支付宝”是个高频词,文章最后说了句:“大家可以分钱了”,那么“分钱”最后也被收录,进入了特征向量.
文章2:“现在过年压岁钱我都是支付宝发”。“支付宝”按例被收录,文章最后总结的时候说“每年过个年,都是在分钱,压岁钱都支付宝发,感觉时代进步真快”,虽然整篇文章“分线”只出现一次,但是还是被收录进入特征向量。
两篇文章的关键词非常类似,但是讲述的却是两个完全不同的事,这个时候机器算法就会出错,将这些相关性弱的文章误以为类似,这个时候推荐出去就会出大事,所以特征向量还需要引入第二个指标,叫词频TF(Term Frequency),衡量每个关键词在文章中出现的频率。
那么又有一个问题,如果两篇文章的关键词重合度很高,词频也和接近,是不是说明关联性就很强呢?大多数情况是这样的,但是也有特殊,比喻某些文章都是将武汉的,武汉美食、武汉大学、武汉互联网、武汉体育等等,这些关键词都包含武昌、汉阳、汉口等,并且都有这相似的频率,那么算法就会误以为他们是相关性极强的文章,所以我们引入一个新的指标,即在所有文章中出现频率的相反值,用IDF(Inverse Document Frequency)表示。这个也很好理解,因为一个词在所有文章出现的频率小,在某篇文章中出现的频率大,这个词就对该篇文章的标识作用越大。因此,关键词对文章的作用衡量出来就为TFIDF=TF*IDF,这个就是著名的TF-IDF模型。
3.算法实现

根据前面几篇文章的内容,两个向量的夹角越小,相似度越高,假设两篇文章的特征向量如下表:
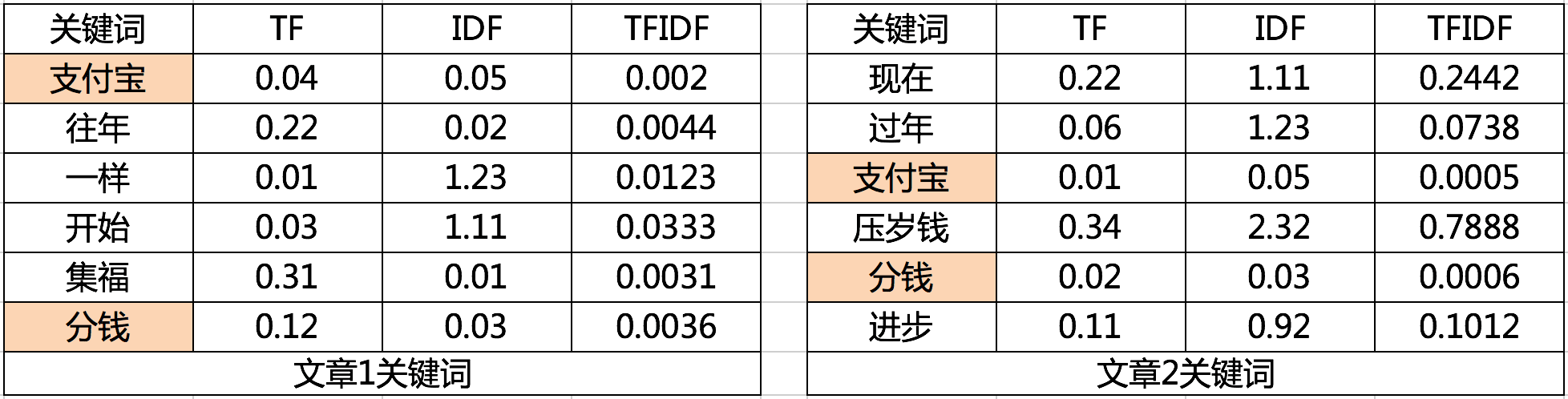
那么这两篇文章就由“支付宝”和“分钱”两个重合关键词决定,根据余弦相似度可以算出两篇文章的相似度,这里不做赘述,有心的朋友可以看看前面的文章。
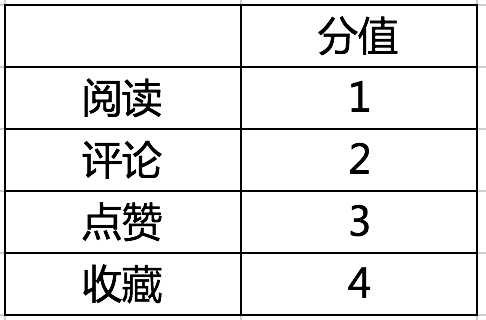
4.用户特征
用户特征类似热度算法一样,根据用户阅读、评论、收藏、转发等行为来赋予一个“钟意度”,例如
那么将文章和用户钟意度结合起来,我们只需要将关键词的TFIDF乘以用户行为特征即可得到用户特征分数。
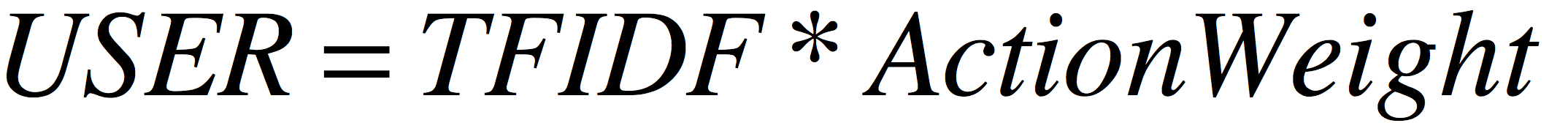
我们有文章特征、用户特征,就能根据根据用户关键词做匹配,得出最符合用户胃口的文章,做出个性化推荐。基于内容的个性化推荐不需要大规模的用户量,无论几亿、几千甚至几百都可以,因此是绝大多数产品前期做推荐的不二首选。
