在数据挖掘和分析的过程中,我们经常需要知道某两个或多个分析对象之间的差异性,从而判别分析对象之间的相似性和所属类别。在数据分析和挖掘领域,用得最多的就是“分类”和“聚类”算法,如:KNN 和 K-Means。今天将主流的一些距离计算算法做一个归纳。
为了方便理解,我们暂定分析的对象只有两个个体 A 和个体 B,并且两个个体在同一个维度:
A(a1,a2,a3…an)
B(b1,b2,b3…bn)
我们先来了解一下相关名词,距离度量(Distance)是用来衡量空间上两个个体之间的距离,接下来一些算法公式中会频繁使用这个概念,我们在公式中用“dist“表示。
欧几里得距离
这是最常见的距离度量公式,读书在数学课本中已有接触,公式如下:
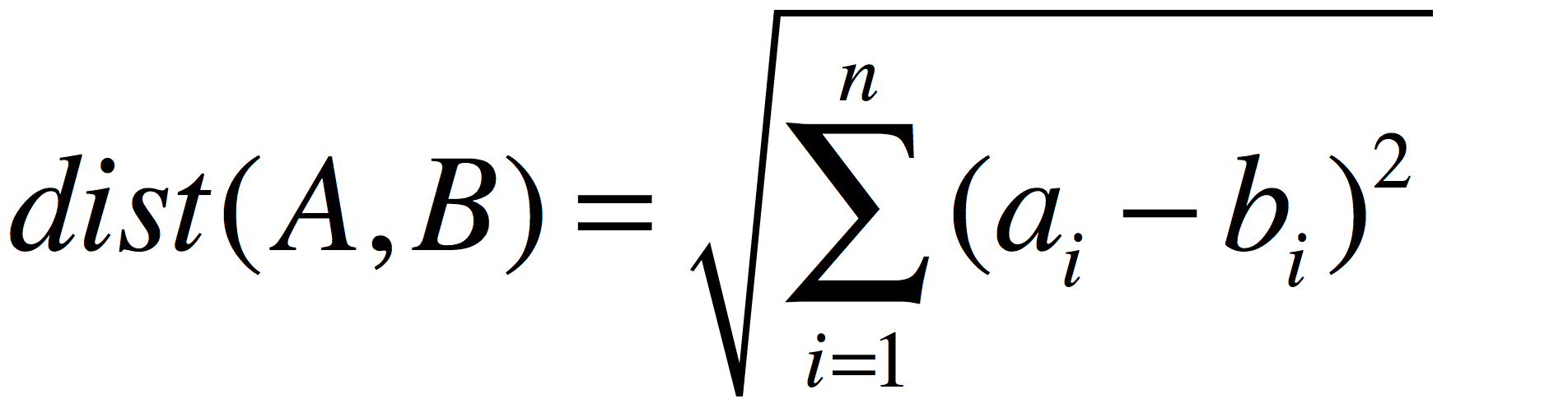
这里需要提醒的是,我们开篇已经注明,是在同一个维度上的两个对象,如果一个描述的是距离(单位M),一个描述的是重量(单位KG),这样比较没有任何意义,也没有可比性。
我们将上面的距离公式做个变形
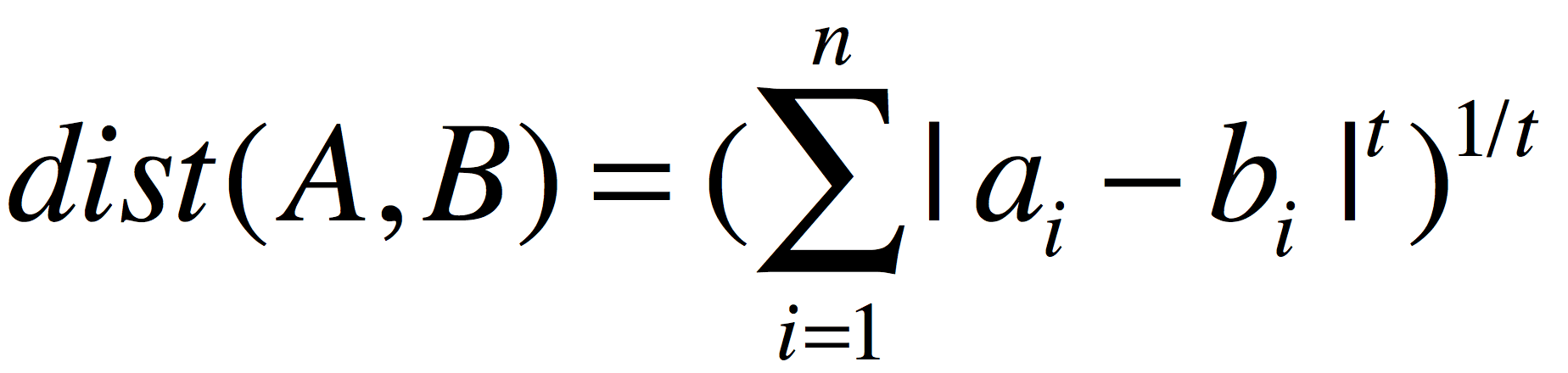
做这样变形的目的就是是上面一些看上去僵硬不变的线条符号用数字表示出来,因为数字的是灵活的,会给人带来启发,如上面的公式中就有人获得灵感,将公式中的“2”用变量代替,结果会如何,这个人叫“明可夫斯基”,最后的距离公式被后人称作:
明可夫斯基距离
当t=2时,明可夫斯基距离公式等于欧几里得距离公式,使用绝对值因为变量t不能确保两者之差为非负数(关于这个问题上篇文章有提到过)。
当t=1时,明可夫斯基距离等于曼哈顿距离。
曼哈顿距离
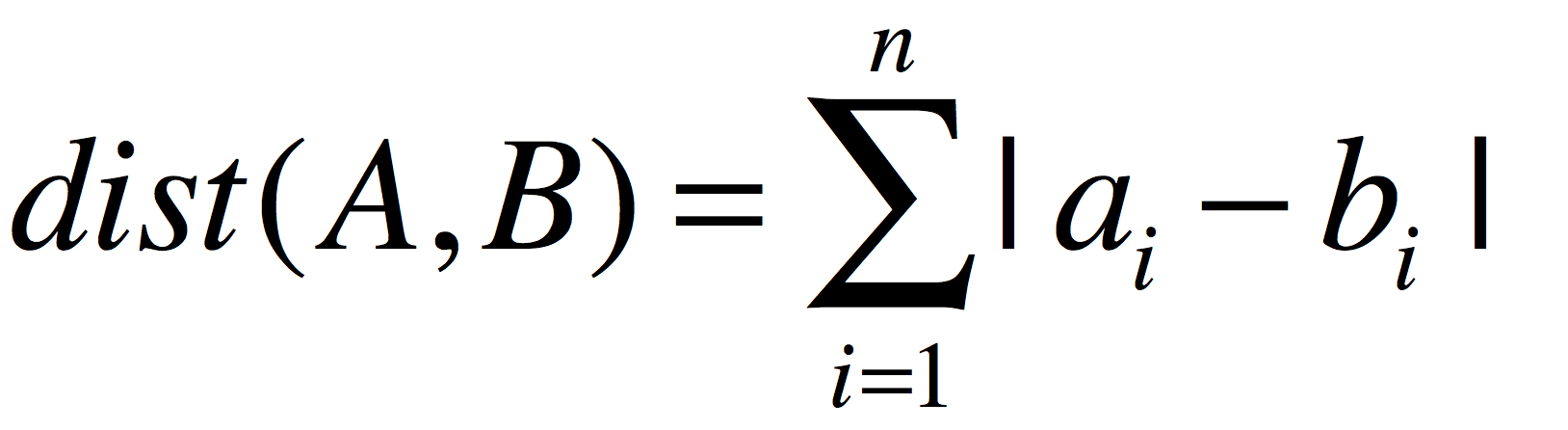
曼哈顿距离依赖座标系统,它还有一个名字叫“城市区块距离”感兴趣的可以移步这里上面看到了当t无限缩小后衍生的距离公式,那么当t无限扩大后又是什么样的结果呢?我们将明可夫斯基距离公式中的“t”放大到无穷大:
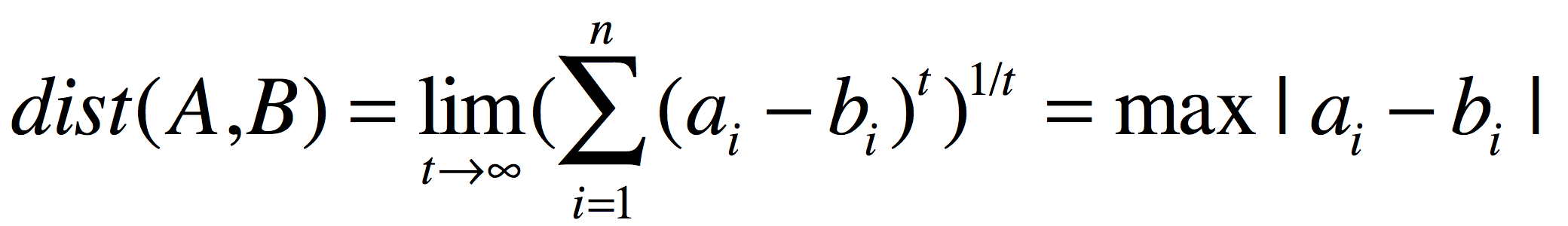
这就变成了“切比雪夫距离”,这些距离都是欧式距离的特殊应用。欧式距离不能忽略比较对象的维度,所以在针对不同维度的比较对象时,需要对数据做标准化处理,这些经过处理后的标准数据,再采用欧式距离比较时有个新的名字:马哈拉诺比斯距离。
余弦相似度
这里有个和“距离度量”类似的名词“相似度度量”,相似度度量(Similarity)在下面的会频繁用到,我们用 “Sim” 表示
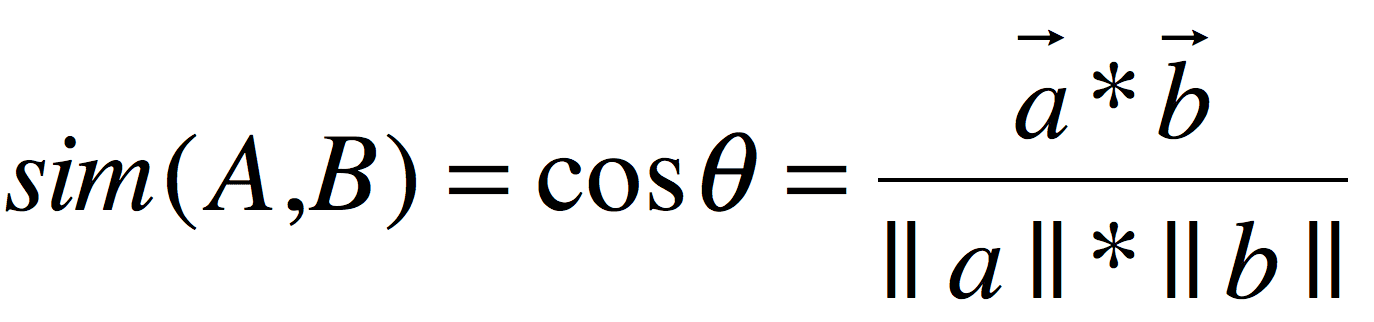
皮尔森相关系数
即相关分析中的相关系数 r,分别对 A 和 B 基于自身总体标准化后计算空间向量的余弦夹角:
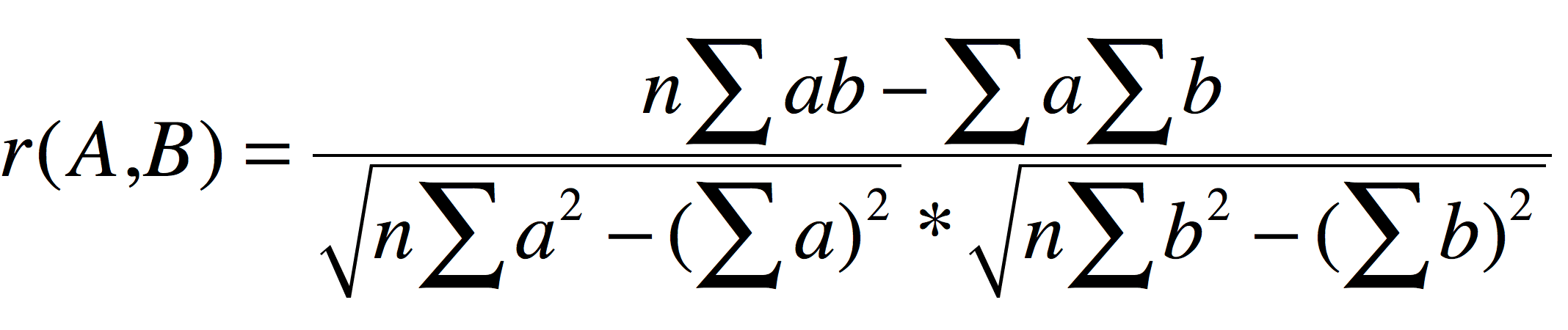
欧氏距离与余弦相似度
欧氏距离是最常见的距离度量,而余弦相似度则是最常见的相似度度量,很多的距离度量和相似度度量都是基于这两者的变形和衍生,所以下面重点比较下两者在衡量个体差异时实现方式和应用环境上的区别。
借助三维坐标系来看下欧氏距离和余弦相似度的区别:
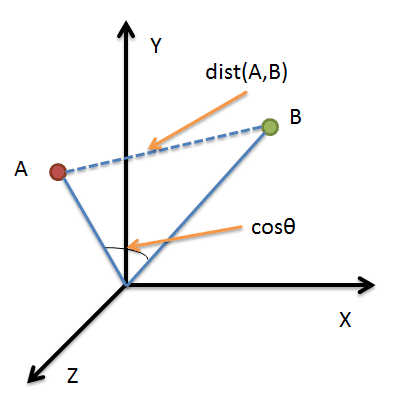
从图上可以看出距离度量衡量的是空间各点间的绝对距离,跟各个点所在的位置坐标(即个体特征维度的数值)直接相关;而余弦相似度衡量的是空间向量的夹角,更加的是体现在方向上的差异,而不是位置。如果保持A点的位置不变,B点朝原方向远离坐标轴原点,那么这个时候余弦相似度cosθ是保持不变的,因为夹角不变,而A、B两点的距离显然在发生改变,这就是欧氏距离和余弦相似度的不同之处。
根据欧氏距离和余弦相似度各自的计算方式和衡量特征,分别适用于不同的数据分析模型:欧氏距离能够体现个体数值特征的绝对差异,所以更多的用于需要从维度的数值大小中体现差异的分析,如使用用户行为指标分析用户价值的相似度或差异;而余弦相似度更多的是从方向上区分差异,而对绝对的数值不敏感,更多的用于使用用户对内容评分来区分用户兴趣的相似度和差异,同时修正了用户间可能存在的度量标准不统一的问题。
在实际应用中都是距离度量和相似度度量结合使用,任何一个算法都是在特定场景下发挥到极致,脱离使用场景,这些伟大的发明仅仅是个公式。
