前几天,旁边的女同事说:“一看到有关《前任3》的新闻报道,我第一时间就想到了吴xx。”于是,我决定去看看这个电影。我想去折腾这个的原因,
不是受“啜泣女孩影响影院正常运作“的新闻,也不是影片的票房,我的动机有两个:
- 和相处近10年的她刚分手(也许某些生活场景我刚经历)。
- 去电影院看是找罪受,爬些数据从另一个角度看,会收获意想不到的效果。
这篇文章,我主要的思路是通过某些网友的观后感受以及对影片的主观评论来解读这部青春剧的网络发酵的原因。那么接下来我需要完成以下几件事:
- 获取这些观后感和主管评论
- 将这些碎片化的文本数据处理成可分析的标准数据
- 建立分析维度,从标准数据中感知数据传递的信息
- 得出结论
获取信息
我先去查看了下30天以来微博的热度指数
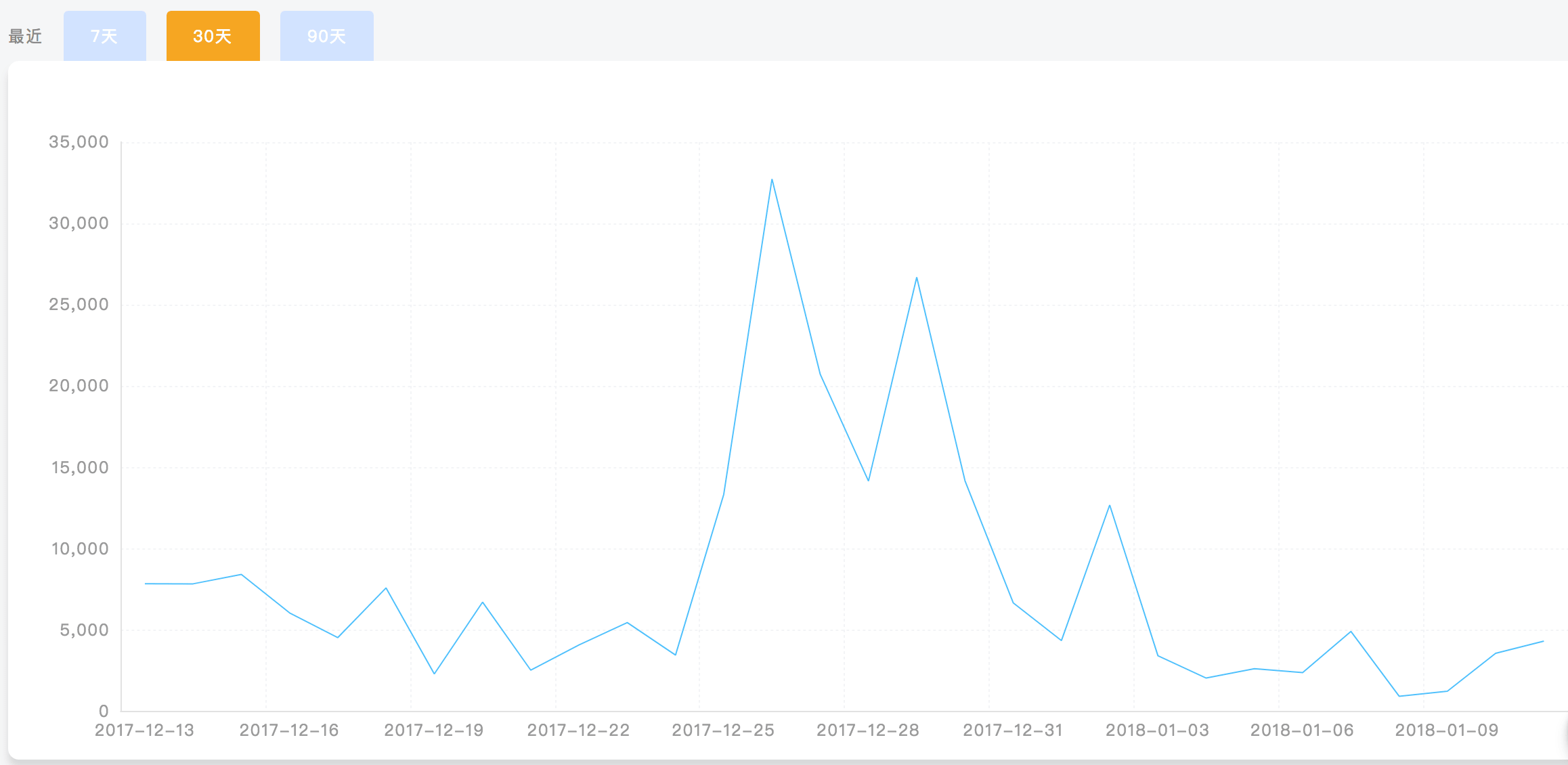
出现这么明显的高峰,很容易想到,这个区间一定处在上映的时间,在26号飙到最高3w多,这不是偶然,每部电影在上映前都会大力铺垫,广告飞上天,呈现的热度也说明了这一点,媒体效应的转化其实是带动一个处于冷却的东西向更热的一端进化。
接下来要正式获取数据了。这是最基础的步骤,你想从事这方面的分析,这个你必须要会。在选择来源的时候,我犹豫了很久,知乎上面的太裝;微博上面太假;网易云音乐我试了,数量不是很大,没有代表性;走而周转,纠结半天,最后还是去了豆瓣,豆瓣上的评论几年前我觉得很有价值,后来慢慢也下海了,今天还是选择了她,也许是出于情怀,也许是出于无奈。
我爬取了豆瓣《前任3》下面的评论,我的目的直接简单,就是要这些评论内容,像“id、链接、喜欢数、时间”等等信息,只是为了以后能再次用得上这张表,今天这里不做赘述。把这些评论处理成文本信息,去掉其中的标点符号,这里提醒一下:像“嗯~啊、~吗”这种语气叹词,最好不要处理,虽然在 nlp 中经常会过滤这些信息,但在这里,这些词有可能代表评论者的某些情绪。如:“嗯~3都出来了啊?还嫌没虐够吗?啊!”当你把这句文本中的“嗯、啊、吗”都去掉,你读一下,绝对感受不到原文本所表达的那种强烈的情绪。所以,数据预处理需要科学的手段也需要理性的经验。
处理信息
将全部评论信息打包,作为语料进行分词,按照词性来分得到以下这张图:
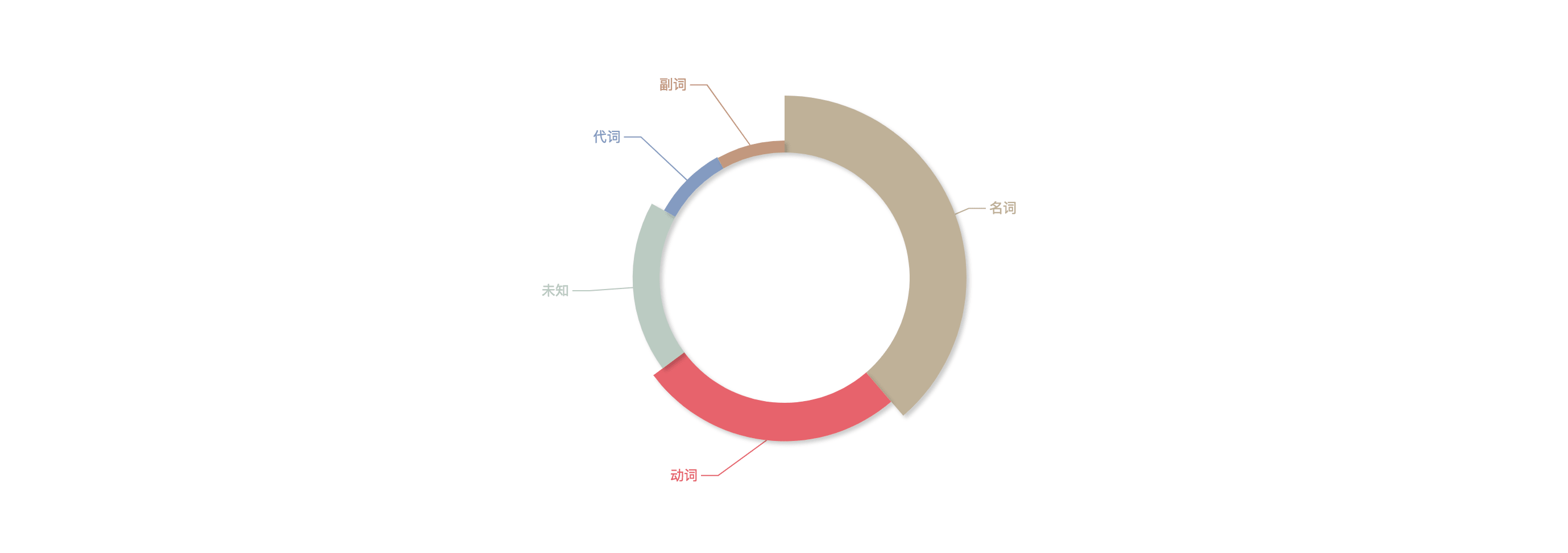
名词占比最多,我们来看看到底是哪些名词出现的次数最多
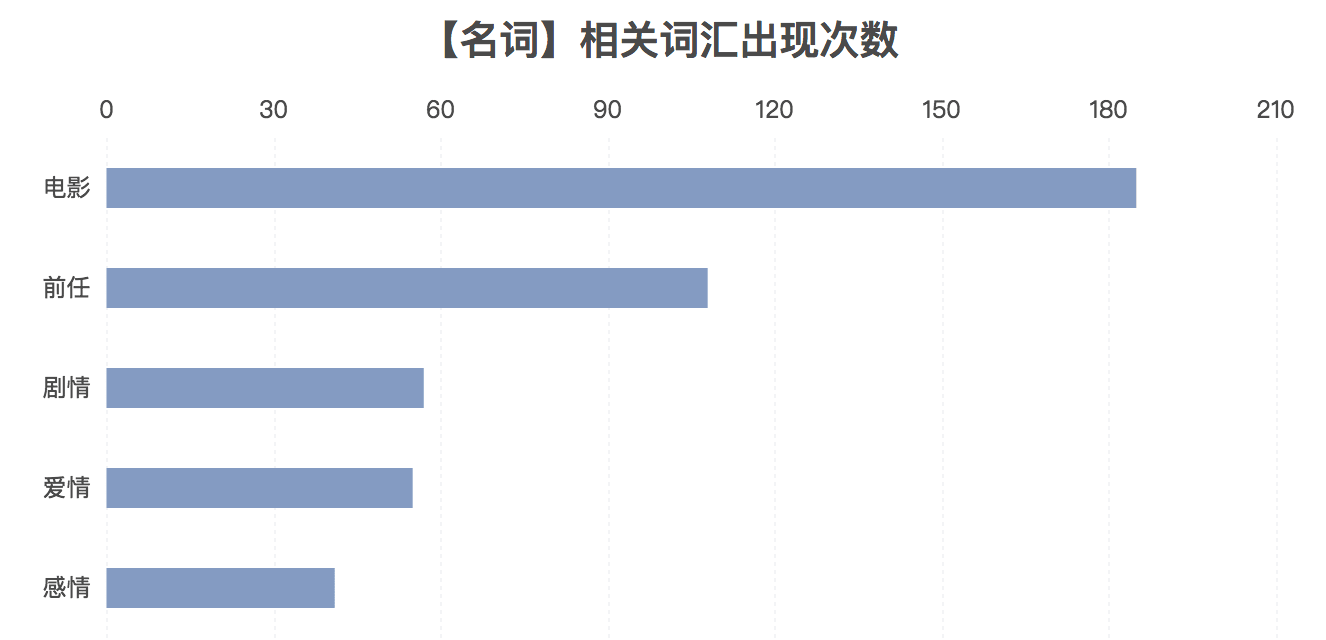
这个很好理解,为什么“电影”会是第一,在大家纷纷发表看法的时候,总会带上主观色彩,于是都在说“很虐心的电影”、“又是一个人看电影”、“这可能是三部中最好的一部电影”;在大家纷纷讨论电影的时候,那些要么分手了,要么分手过,要么快分手的人在说“我的前任早死了,哈哈哈!”,“嗯,我前任渣到至今我没法忘记”或者是“我还在等我前任”“前任1、2没这个好看”等等一系列的话题。前任死没死不重要,重要的是“前任”这个词和“爱情”是分不开的,他们在现实中是前因后果,在实际中是“豆浆油条”只要出现,总是“凝固”得最紧。爱情伴随感情而生,日久生情是建立在有感情的的基础上,多少爱情不就是小时候她帮我背了几个单词这点小感情而来的吗?
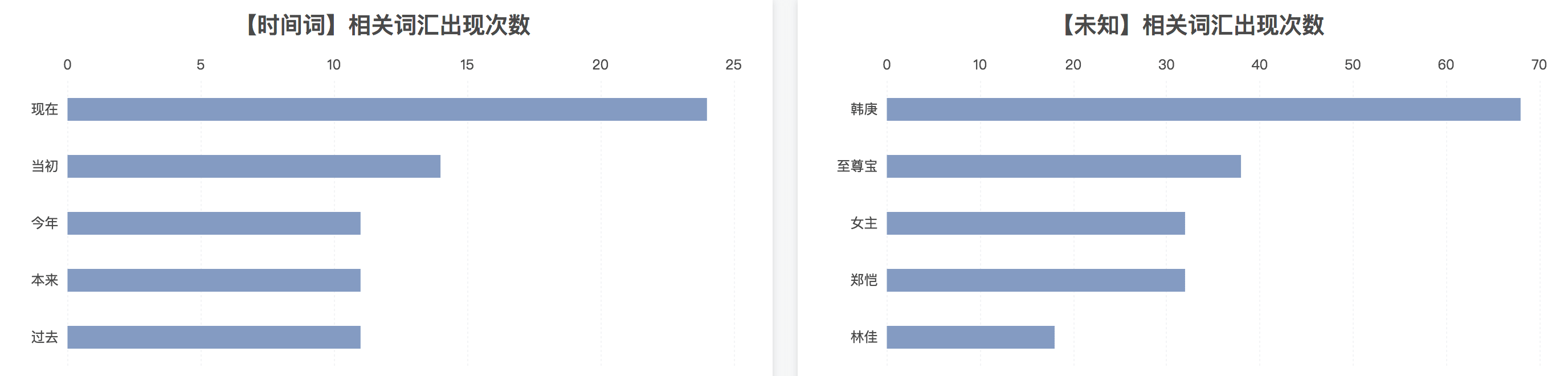
“(本来)曾经(当初)有一份真诚的爱情放在我面前,我没有(过去)珍惜,等我失去的时候我才后悔莫及,人世间最痛苦的事莫过于此。如果(未来)上天能够给我一个再来一次的机会,我会对那个女孩子说三个字:我爱你。”在爱情面前,没有忏悔的机会,失去得是青春不是某一个人。这一连串的时间维度的词不禁让人感叹,回忆和梦想是现实中最好的补给品。这几个主角的名字也成了评论的焦点,”至尊宝“是个什么我不清楚,应该是剧中直接或间接植入的某个广告吧,名字中只认识郑恺,貌似名字男生多一些,我猜测在我所爬到的数据中评论者的性别女性多一些。
关系链,整个网友《前任3》为中心,360度蔓延,语义分析的维度有很多很多,不同的分析会得到不同的结果,既可以做出运营调整报告,也可以做出产品决策书,大到可以作为商业投资依据等等。因为文本包含的信息是含有感情色彩的,这比那些死板的数据带来的信息多很多。

分析
某些分析已经从基本的词频、词类说过,这是一个维度的分析,直接简单,好理解。但是从文本数据表达来感知评论者的喜、怒、哀、乐等分析(行内称“情感分析”),比较复杂,这里说一下具体的思路,(会有些枯燥,不想看的同学直接跳过)将处理的文本分词后与一个已有的词库进行对比,这个词库包含喜、怒、哀、乐等情感词,统计完成后,将的词与原有的感情库数据对比,算出一个分值,如:“真伤心,好虐心的电影”中把”伤心、虐心“等词归纳到感情色彩词”哀”,将各个类别一起完成,形成权重分值,挨个执行之后,整个文本就会由这些附带感情色彩的情感词组成啦

这部电影表达了一个负面的感情过程,评论自然不会是积极向上的,待定人物的负面得分稍微高一些(数据量越大,这个越明显),这个是数据永远遵循的规律,数据反应真实的结果,数据也遵循客观规律。
上面有些内容需要很专业的知识,有的还需要程序来支持,这里给大家介绍一下相关的工具和免费在线系统:
python(数据分析处理的神级语言)
Jieba分词(分词库,挺好用的)
Bdp(可视化)
Gensim(词向量、主题模型)
bokeh(可视化)
plotly(可视乎)
图锐(在线做词云,免费)
新浪微舆情(舆情分析系统,可试用)
excel(很多数据都可以通过它预先处理)
烽火普天(在线文本处理)
文本分词后做的词云

结论
- 一部电影出来后可以在一段时间上影响一群人的情绪,看这部电影看哭的人很多。
- 在大家理性评论的时候,有些人已经忘记前任,放松看开了,喜上心头;有些人坠入爱河,痛极生悲;有多少个前任就有多少个悲剧,韩庚也好,郑恺也罢,生活是自己的,提醒大家爱自己,爱他人。
- 任何一部电影都会有明星效应,吐槽评论之间,主角什么的都会成为话题,红不红火不火颜值占一部分,角色占一部分。
- 一部电影播出,除了票房收益,还可能让不红的演员红起来,让很红的演员掉一波粉,某些广告可能销量剧增,甚至同款拖鞋内裤纷纷爆上某宝首页。
很多看似很平凡的逻辑推理,在数据的驱动下显得更有说服力,不是数据有强大,只是让那些喜欢反驳的人少了一个扯淡的理由,任何一项分析、预测、推荐不是100%的达到预期效果,但是只要执行下去,优化算法,加以人员运营,总会慢慢变好,这是社会的趋势,也是发展的必要。本文从“为什么要做这个分析>>分析什么>>怎么分析>>分析结果”等流程来阐述整个文本文本语义分析的流程,中间很多处理数据、计算、模型选择等都没有阐述,主要是这片文章旨在给在职的 pm 一个互相学习的机会,有机会的话,下次的文章将会针对技术一点,从写爬虫>>excel预处理>>文本分词>>词性分类>> 情感话分析权重比对等过程。
我是一枚数据 pm,有态度,有追求,有情怀。只希望在未来的某一天,数据驱动产品迭代、决策、运营能够成为行内标配。
